OCR Analysis
이미지 속의 언어 해독: OCR 기술을 활용한 업무 효율성 향상
OCR(광학 문자 인식) 기술은 이미지 내의 텍스트를 인식하고 추출하는 혁신적인 기술로, 다양한 분야에서 광범위하게 활용되고 있습니다. 이 기술은 원래 문서를 디지털 데이터로 변환하는 데 사용되었으며, 시간이 지남에 따라 그 기능과 정확도가 크게 향상되었습니다. OCR의 역사는 초기 타자기에서부터 최신 딥러닝 기반 알고리즘까지 이르며, 이러한 발전은 비즈니스 프로세스를 자동화하고 일상 생활을 간소화하는 데 크게 기여하고 있습니다.
OCR 기술의 기본 원리는 간단하면서도 복잡합니다. 이미지 캡처부터 시작하여, 전처리 과정을 통해 이미지를 최적화하고, 문자를 분리한 뒤 인식하고, 최종적으로 후처리 과정을 거쳐 결과를 출력합니다. 이 과정에는 다양한 알고리즘과 기술이 사용되며, 특히 딥러닝과 패턴 인식 기술은 OCR의 정확도와 효율성을 대폭 향상시키는 데 중요한 역할을 합니다.
이미지 내에서 텍스트가 존재하는 영역을 찾아내는 과정으로, 이 단계의 목표는 이미지 상에서 문자가 있는 위치를 식별하고, 그 경계를 정의하는 것입니다. 텍스트 검출은 다양한 배경, 폰트, 크기의 텍스트를 다루기 위해 고도화된 알고리즘을 사용합니다. 이 과정은 이미지에 있는 비텍스트 요소(예: 그림, 배경)를 필터링하고, 텍스트 영역만을 분리해내는 작업을 포함합니다. 텍스트 검출의 성공 여부는 후속 단계인 텍스트 인식의 정확도에 큰 영향을 미칩니다.
텍스트 검출 단계를 통해 식별된 텍스트 영역에 대해, 텍스트 인식은 그 안에 포함된 문자나 단어를 실제로 읽어내는 과정입니다. 이 단계는 인식된 텍스트 영역 내의 각 문자를 분석하고, 이를 디지털 텍스트 데이터로 변환합니다. 텍스트 인식 과정은 문자를 식별하기 위해 패턴 인식, 기계 학습, 딥러닝 등의 기술을 활용합니다. 이 과정에서 OCR 시스템은 다양한 스타일과 손글씨 또는 인쇄된 텍스트를 정확하게 인식할 수 있어야 합니다.
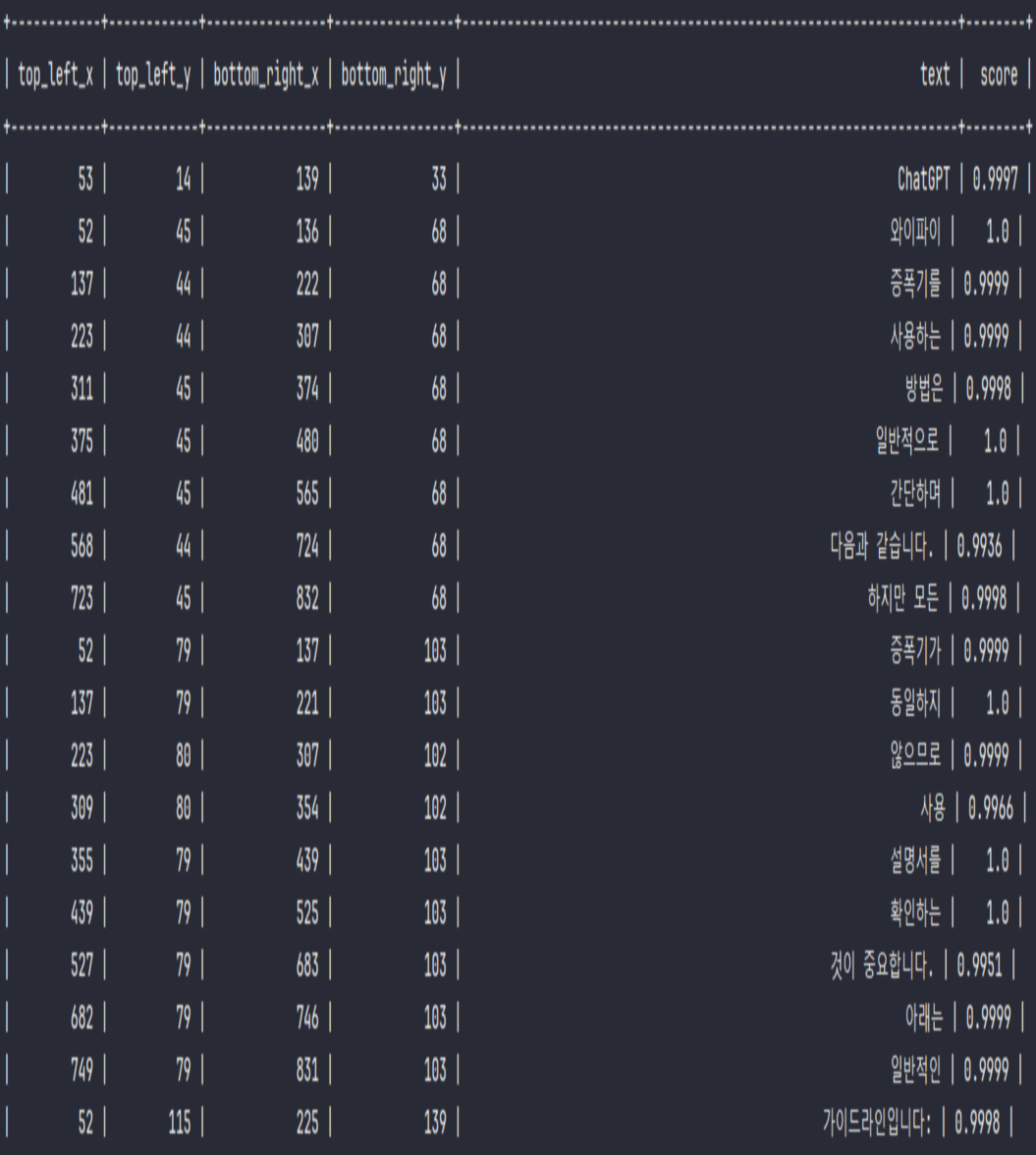
이미지에서 글자 추출하기
이 과정은 고급 문자 인식(OCR) 기술을 활용하여 시각적 자료로부터 텍스트 정보를 추출하고, 이를 디지털 형태의 데이터로 재구성하여, 필요한 시스템이나 데이터베이스로의 효율적인 전송을 가능하게 합니다.
이러한 방식은 데이터 처리와 분석의 자동화를 촉진하며, 정보 접근성 및 활용도를 대폭 개선시킵니다.

OCR Before

OCR After 1