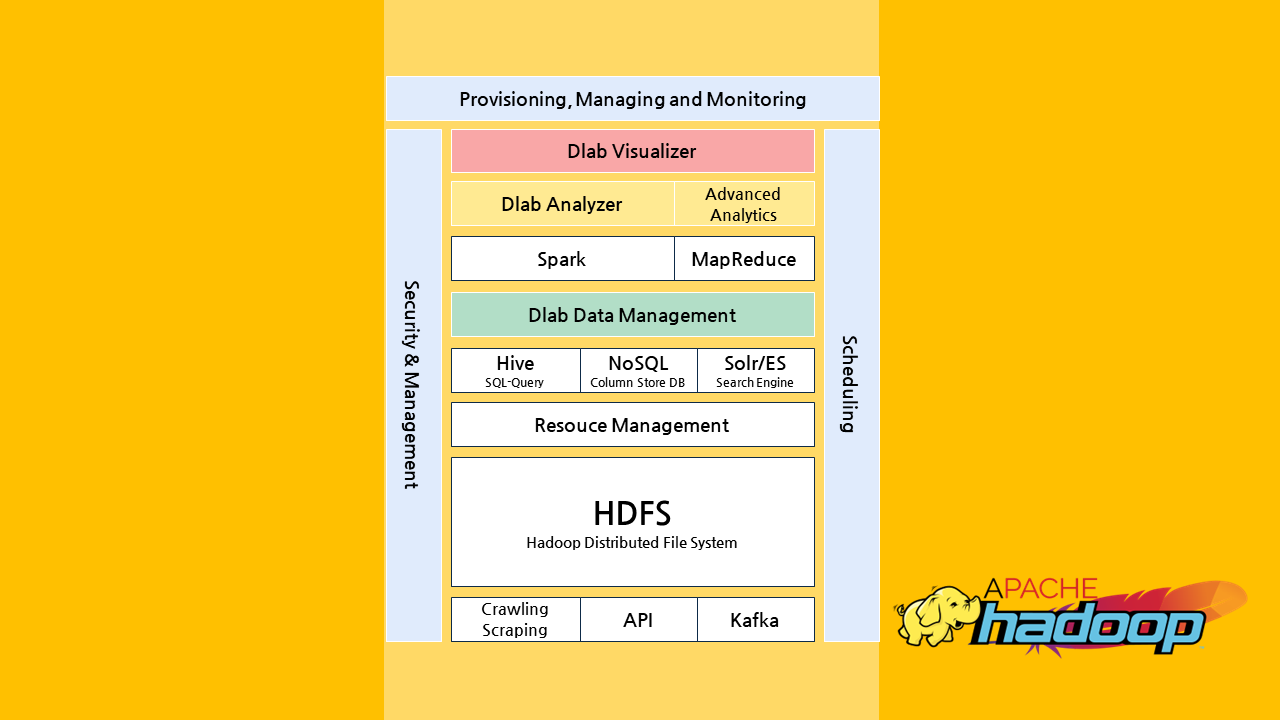
Big Data Platform
하둡을 활용한 빅데이터 분석
Hadoop은 대규모 데이터셋을 효율적으로 처리하기 위해 설계된 오픈소스 프레임워크로, 복잡하고 다양한 데이터의 처리 및 분석을 가능하게 하는 분산 컴퓨팅 환경을 제공합니다. 이의 핵심 구성 요소인 HDFS(Hadoop Distributed File System)는 대용량 데이터를 저장하고, 빠른 데이터 접근과 신뢰성을 보장하는 분산 파일 시스템으로서, 데이터의 무결성과 확장성을 지원합니다. 또한, Hive는 Hadoop 위에서 구축되는 데이터 웨어하우스 시스템으로, SQL과 유사한 HQL(Hive Query Language)을 사용하여 대규모 데이터셋에 대한 쿼리 및 분석을 수행합니다.
이러한 통합된 아키텍처는 기업이나 조직이 비용 효율적으로 맞춤형 데이터 솔루션을 구축할 수 있도록 지원하며, 데이터의 복잡성과 양이 지속적으로 증가하는 현대의 비즈니스 환경에서 높은 유연성과 확장성을 제공합니다.
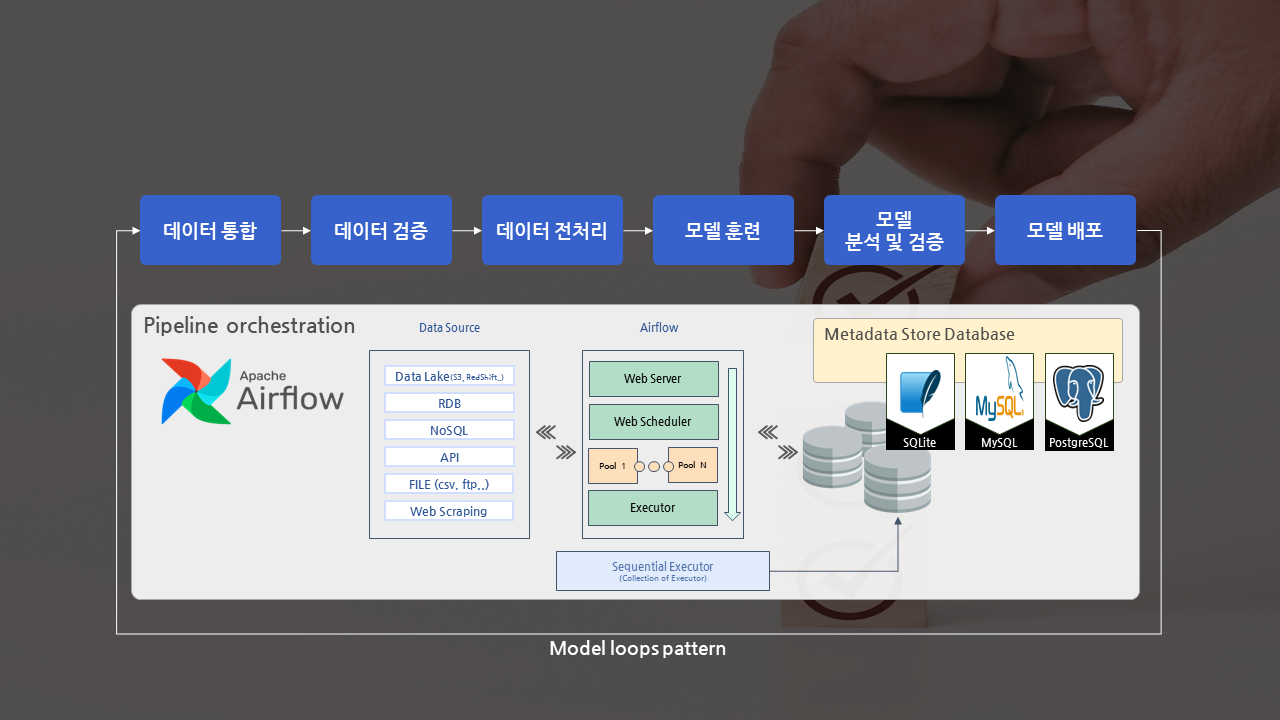
데이터 파이프라인
여러 분야에서 수집된 데이터가 안정적으로 수급되고 있는지 Airflow 또는 StreamSets를 통해 모니터링하며, 이 도구들은 데이터의 수집, 변환 및 로드 과정을 자동화하고, 파이프라인의 성능과 안정성을 지속적으로 감시하고 최적화합니다. 이를 통해 데이터의 품질과 신뢰성을 보장하고, 비즈니스 의사 결정 및 분석에 필요한 정확하고 실시간의 데이터를 제공합니다.
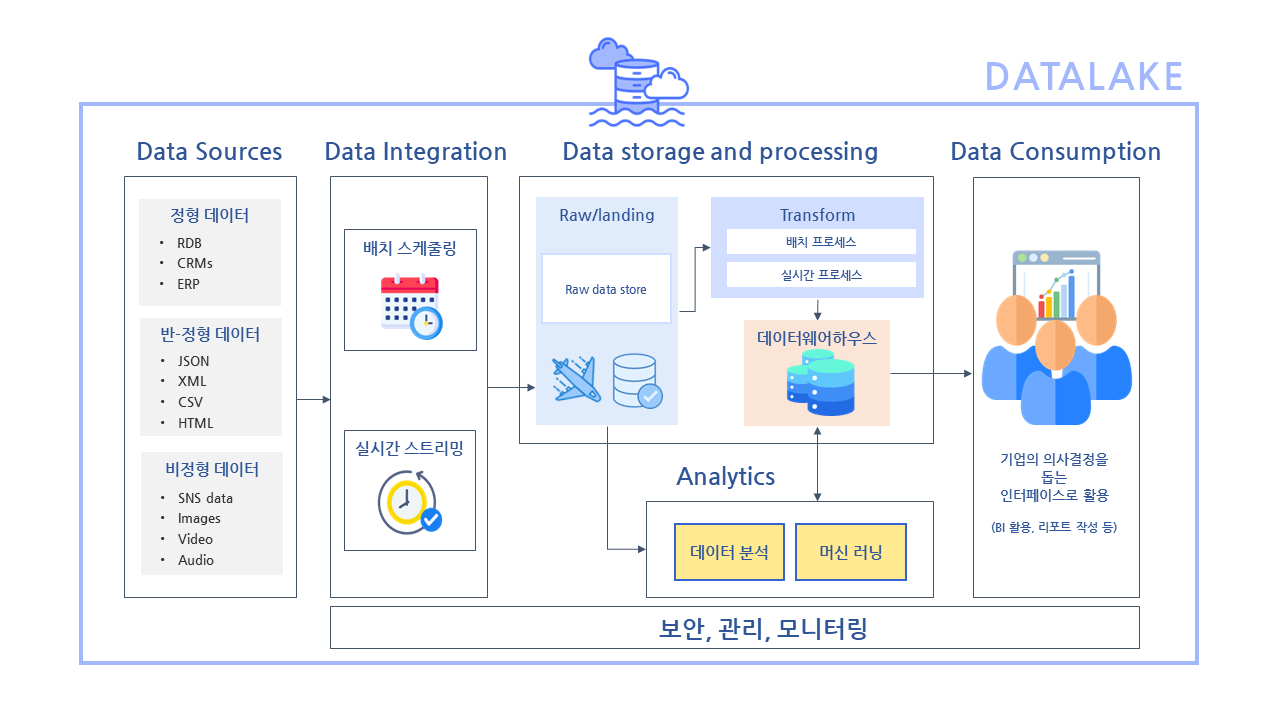
데이터레이크
데이터 레이크는 테이블과 레코드 형태의 구조화된 데이터, 키-값 쌍 또는 임의의 스키마를 가진 반구조화된 데이터, 그리고 메타데이터 또는 스키마 없이 저장되는 비구조화된 데이터 등, 다양한 데이터 포맷을 수용하는 대용량 데이터 저장 및 관리 시스템입니다. 이 시스템은 원본 형태의 데이터를 효율적으로 수집, 저장하며, 빅데이터 분석, 머신러닝, 실시간 데이터 처리와 같은 고급 데이터 처리 작업을 지원합니다.
데이터 레이크는 데이터 웨어하우스와 달리 유연한 스키마 온 리드(Schema-on-Read) 접근 방식을 채택하여, 데이터의 원시 형태를 유지함으로써 더 다양하고 동적인 분석이 가능하도록 합니다. 이는 빅데이터 시대에 조직들이 빠르고 유연하게 대응할 수 있는 데이터 관리 전략의 핵심 요소로 자리 잡고 있습니다.